Designing a news feed like Instagram or Facebook is a classic system design interview question. It tests your ability to handle massive scale, “fan-out” problems, and the balance between write-heavy and read-heavy workloads.
Table of Contents
Open Table of Contents
- Interview Framework: How to Approach This Problem
- Step 1: Clarifying Requirements
- Step 2: Core Assumptions and Constraints
- Step 3: High-Level Architecture
- Step 4: The Hardest Problem - Feed Generation Strategies
- Step 5: Key Technical Decision - Push vs. Pull vs. Hybrid
- Step 6: Database Design and Storage
- Step 7: Scaling the System
- Step 8: Security and Permissions
- Step 9: Handling Edge Cases
- Step 10: Performance Optimizations
- Real-World Implementations
- Common Interview Follow-Up Questions
- Q: How would you add “Stories” (disappearing content)?
- Q: How do you handle algorithmic ranking?
- Q: How do you handle users with 100M followers without melting fan-out workers?
- Q: How do you delete or edit posts and keep home feeds correct?
- Q: How would you defend feed quality against spam and bot engagement?
- Conclusion
- References
- YouTube Videos
Interview Framework: How to Approach This Problem
In a system design interview, when asked to design Instagram’s Feed, here’s the structured approach you should follow:
- Clarify requirements (5 minutes) - Focus on what the “feed” actually contains.
- State assumptions (2 minutes) - Define the scale (it’s huge).
- High-level design (10 minutes) - Map out the user, post, and feed generation flow.
- Deep dive (20 minutes) - The “Fan-out” service is the heart of this problem.
- Scale and optimize (10 minutes) - Caching strategies are critical here.
- Edge cases (3 minutes) - Celebrity users (“The Justin Bieber problem”).
Key mindset: This is primarily a read-heavy system for most users, but the write load triggers a massive amplification effect (fan-out).
Step 1: Clarifying Requirements
Questions to Ask the Interviewer
Q: Is the feed chronological or algorithmic (ranked)?
- Answer: Let’s assume chronological for MVP, but the system should support ranking.
Q: What types of content are in the feed?
- Answer: Photos and videos from people you follow.
Q: Do we need to handle “celebrity” accounts with millions of followers?
- Answer: Yes, absolutely.
Q: What is the scale?
- Answer: 1 Billion users, 500 Million Daily Active Users (DAU).
Functional Requirements
- News Feed: Users can view a feed of posts from people they follow.
- Post Creation: Users can upload photos/videos.
- Following: Users can follow/unfollow others.
- Infinite Scroll: The feed keeps loading new content.
Non-Functional Requirements
- Low Latency: Feed generation must be near real-time (under 200ms).
- High Availability: The service should always be up (99.99%).
- Eventual Consistency: It’s okay if a friend’s post takes a few seconds to appear in my feed.
- Reliability: Photos/videos must never be lost.
Step 2: Core Assumptions and Constraints
To design for the right scale, we need some back-of-the-envelope calculations.
Traffic Estimates
- 500 Million DAU.
- Assume each user views the feed 5 times/day.
- Total Impressions: $500M \times 5 = 2.5 \text{ Billion views/day}$.
- Reads per second (QPS): $2.5B / 86400 \approx 30,000 \text{ QPS}$ on average. Peak maybe 2-3x.
Storage Estimates
- Assume 10 Million posts/day.
- Photo size avg: 200KB.
- New Storage/day: $10M \times 200KB = 2TB / \text{day}$.
- Over 10 years: $\approx 7.3PB$. We need huge blob storage (S3).
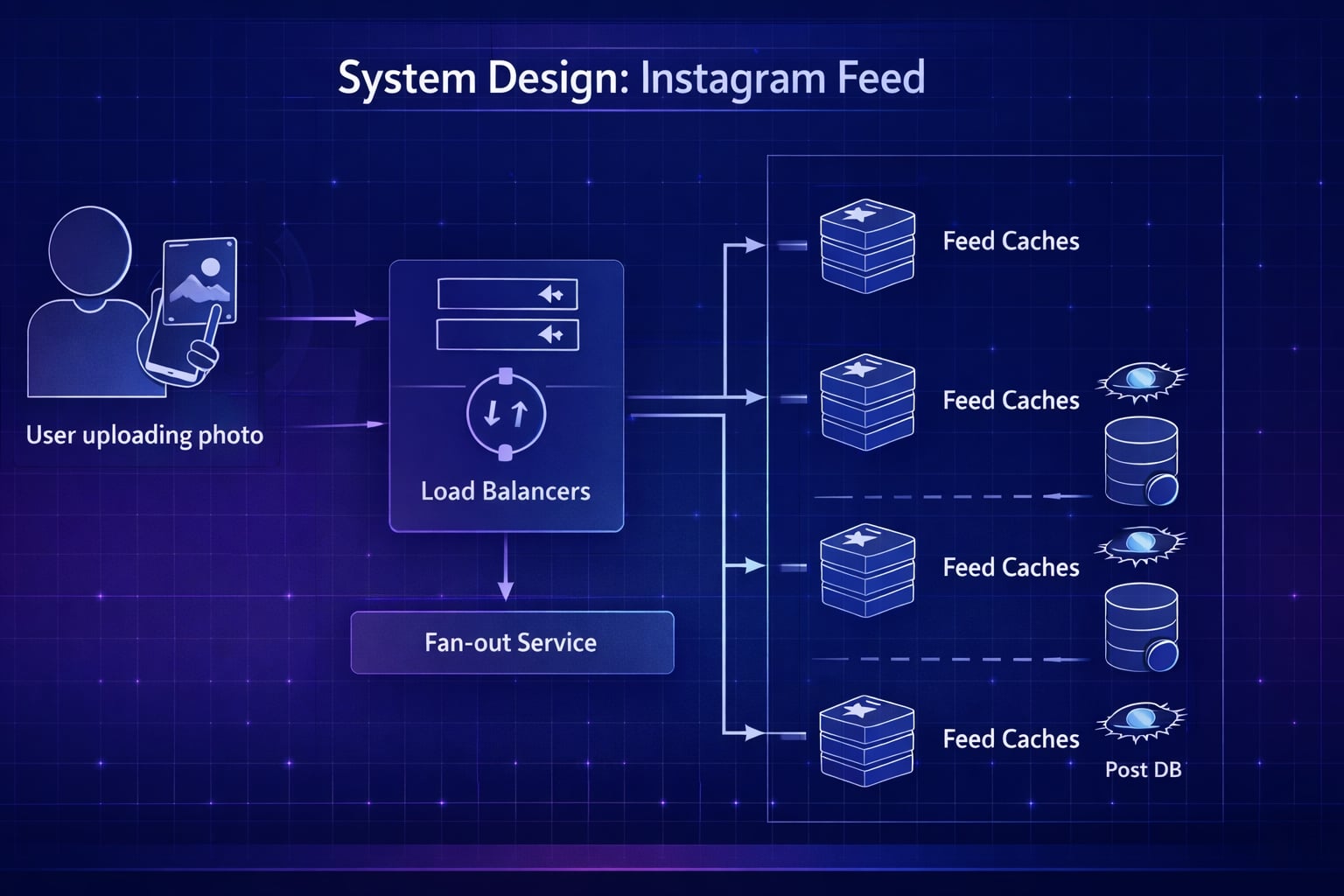
Step 3: High-Level Architecture
“Let me map out the high-level architecture separating the Write path (posting) from the Read path (viewing feed).”
System Flow Diagram
flowchart TD
Client[Client App] --> LB[Load Balancer]
LB --> Web[Web Servers]
subgraph Services ["Backend Services"]
direction TB
PostSvc[Post Service]
FanoutSvc[Fan-out Service]
FeedSvc[Feed Service]
MediaSvc[Media Service]
end
subgraph Data ["Data Storage"]
direction TB
PostDB[(Post DB<br/>Cassandra)]
UserDB[(User DB<br/>SQL)]
Redis[(Feed Cache<br/>Redis)]
S3[(Media Storage<br/>S3)]
end
Web --> PostSvc
Web --> FeedSvc
Web --> MediaSvc
PostSvc --> PostDB
PostSvc -.->|Async Event| FanoutSvc
FanoutSvc -->|Get Followers| UserDB
FanoutSvc -->|Push Updates| Redis
FeedSvc -->|Get Feed IDs| Redis
FeedSvc -->|Hydrate Posts| PostDB
MediaSvc --> S3
classDef service fill:#e1f5fe,stroke:#01579b,stroke-width:2px,color:#000000;
classDef storage fill:#fff3e0,stroke:#e65100,stroke-width:2px,color:#000000;
classDef client fill:#f3e5f5,stroke:#4a148c,stroke-width:2px,rx:10,ry:10,color:#000000;
class Client,LB,Web client;
class PostSvc,FanoutSvc,FeedSvc,MediaSvc service;
class PostDB,UserDB,Redis,S3 storage;Data Flow (Write Path)
- User uploads image -> Media Service (stores to S3).
- User creates post metadata -> Post Service (writes to DB).
- Post Service triggers Fan-out Service.
- Fan-out Service fetches followers and pushes post ID to their feeds in Feed Cache.
Data Flow (Read Path)
- User requests feed -> Feed Service.
- Feed Service fetches list of Post IDs from Feed Cache.
- Hydrates post details (caption, user info) from Post Service/User Service.
- Returns JSON to client.
Why This Architecture?
- Decouples Feed Generation from Feed Reading: Reading happens from a pre-computed cache (fast). Writing handles the complexity of distribution.
- Specialized Storage: Blob storage for images, NoSQL for posts (high write volume), Redis for feed lists (fast access).
Step 4: The Hardest Problem - Feed Generation Strategies
“Now let’s tackle the core challenge: How do we generate the feed efficiently?”
Option 1: Pull Model (Fan-out on Read)
When a user requests their feed:
- System fetches all people the user follows.
- Queries the Post DB for recent posts from all those people.
- Merges and sorts them in memory.
- Returns the result.
Pros: Simple write path. Cons: Very slow for users who follow many people. Database intensive. High latency on read. Verdict: ❌ Not suitable for Instagram scale reading.
Option 2: Push Model (Fan-out on Write)
When a user creates a post:
- System fetches all their followers.
- Pushes the Post ID to the “feed list” of every follower in a cache (e.g., Redis).
- When a follower reads their feed, they just read their pre-computed list.
Pros: Read complexity is O(1) - ultra fast. Cons: Write complexity is O(N) where N is follower count. The “celebrity problem”. Verdict: ✅ Excellent for 99% of users.
Step 5: Key Technical Decision - Push vs. Pull vs. Hybrid
“I recommend a Hybrid Approach to handle different user types.”
The Fan-out on Write (Push) model fails for celebrities. If Justin Bieber (100M+ followers) posts, the system tries to update 100M redis keys simultaneously. This is the Thundering Herd problem.
The Hybrid Solution
- For Regular Users (Few followers): Use the Push Model. When they post, immediately push to all followers’ feed caches.
- For Celebrities (Many followers): Use the Pull Model. When they post, just write to the DB. Do NOT fan-out.
- For Reading the Feed:
- Retrieve the pre-computed feed (from regular friends).
- At read-time, explicitly pull/merge updates from the celebrities the user follows.
Why this works: It keeps reads fast for the majority of data, while preventing system lag during major events (celebrity posts).
Step 6: Database Design and Storage
Data Classification
1. User Data (Profile, Relations)
- Storage: Relational DB (PostgreSQL/MySQL) or Graph DB (Neo4j).
- Why: Structured data, strict relationships. Graph DB makes “Get Followers” queries efficient.
2. Post Metata (ID, Caption, Timestamp)
- Storage: Cassandra or DynamoDB.
- Why: Massive write throughput, simple key-value patterns, infinite scaling.
3. Feed Data
- Storage: Redis (Sorted Sets).
- Why: We need O(1) access to “User X’s Feed”. Redis Sorted Sets are perfect for keeping a time-ordered list of Post IDs.
Schema Design (Simplified)
User Table (SQL)
id: PK
username: varchar
email: varchar
creation_date: datetimeFollow Table (SQL or Graph Edge)
follower_id: FK
followee_id: FK
timestamp: datetime
-- Index on both columnsFeed Cache (Redis)
# Key: "user:feed:12345"
# Value: Sorted Set of Post IDs by timestamp
ZADD user:feed:12345 1675840000 "post_98765"Step 7: Scaling the System
“Let’s discuss how to scale to 500M DAU.”
Feed Cache Scaling
We cannot store all feeds in one Redis instance. Solution: Sharding.
- Sharding Key: UserID.
hash(user_id) % number_of_redis_nodesdetermines which server holds a user’s feed.- Use consistent hashing for easier node addition/removal.
Post DB Scaling
Cassandra handles this naturally. We choose a Partition Key of post_id or user_id depending on query patterns.
- If querying posts by user: Partition Key =
user_id. - Clustering Key =
timestamp(descending) to fetch newest posts quickly.
Media Scaling (CDN)
- Images/Videos are stored in S3 (Blob Storage).
- Use a CDN (CloudFront/Akamai) to serve media closer to users.
- This reduces latency and offloads traffic from our servers.
Step 8: Security and Permissions
“Security is critical for private content.”
Permission Model
- Public Accounts: Feed generation is straightforward.
- Private Accounts: The Fan-out service must check
is_approved_followerbefore pushing content.
Authentication
- Use OAuth 2.0 / JWT for API requests.
- SSL/TLS termination at the Load Balancer.
Step 9: Handling Edge Cases
Edge Case 1: Inactive Users
Problem: Why compute feeds for users who haven’t logged in for months? Wasted storage. Solution:
- Stop pushing to feed caches of users active for > 15 days.
- If they return, “rebuild” the feed on-the-fly (Pull model) and resume pushing.
Edge Case 2: “The Thundering Herd” (Celebrity Post)
Problem: 100M writes clog the queues. Solution: Addressed by the Hybrid Model. Celebrity posts are pulled, not pushed.
Step 10: Performance Optimizations
“Here are key optimizations to keep it under 200ms:“
1. Feed Size Limit
Don’t store the user’s entire history in Redis. Keep only the last ~500-1000 Post IDs. If they scroll past that, fetch older data from the DB (pagination).
2. Pre-fetching
When a user opens the app, pre-fetch images for the top 5 posts in the viewport so they appear instantly.
3. Asynchrony
The “Post” endpoint should return “Success” immediately after persisting the post metadata. The Fan-out process should be completely asynchronous (via Message Queues like Kafka).
Real-World Implementations
Instagram’s Evolution
- Early Days: Started with PostgreSQL on EC2.
- Scaling: Moved massive data to Cassandra for reliability.
- Feed: Uses a complex ranking algorithm (EdgeRank derivative) now, but the underlying push/pull architecture concepts remain valid.
Facebook News Feed
- Uses a proprietary “Aggregator” layer (Leaf nodes and Root nodes) to pull and sort stories in real-time.
- Heavily optimized for fan-out on read (Pull) because the graph is bi-directional (Friends), unlike Instagram’s uni-directional (Follows).
Common Interview Follow-Up Questions
Q: How would you add “Stories” (disappearing content)?
Answer: I’d model Stories as a separate timeline product with strict TTL:
- Store metadata in a Stories service, media in object storage, and viewer states in a fast key-value store.
- Enforce 24-hour expiration with server-side TTL, not only client logic.
- Keep fan-out lightweight by indexing only active stories for followers.
- Batch write view receipts to reduce write amplification.
Trade-off: Strong expiration guarantees add backend complexity, but they protect product behavior and legal expectations.
Q: How do you handle algorithmic ranking?
Answer: I would separate candidate generation from ranking:
- Generate 500-1000 candidate posts from graph, recency, and engagement signals.
- Rank with a model using affinity, freshness, predicted watch time, and quality signals.
- Apply business rules after ranking (ads spacing, diversity, safety filters).
- Precompute top candidates for heavy users and refresh incrementally.
Trade-off: Better relevance increases CPU cost and model serving latency, so we budget scoring time per request.
Q: How do you handle users with 100M followers without melting fan-out workers?
Answer: I would use a hybrid push/pull strategy:
- Push model for normal users (fast reads, predictable timeline).
- Pull model for celebrity accounts (store post once, merge on read).
- Keep a per-user “home feed cache” that merges push items with celebrity pulls.
- Use async backfill to smooth spikes after viral events.
This avoids a write explosion when a celebrity posts while preserving a fast read experience.
Q: How do you delete or edit posts and keep home feeds correct?
Answer: I treat edits/deletes as high-priority events:
- Publish a tombstone/update event to feed workers.
- Remove or rewrite cached feed entries using post ID index.
- Enforce hard checks at read time so stale cache entries cannot leak removed content.
- Replay event logs for repair if a worker fails.
Trade-off: Repair logic adds complexity, but content integrity and moderation correctness are non-negotiable.
Q: How would you defend feed quality against spam and bot engagement?
Answer: I would add abuse controls in multiple layers:
- Risk score users and posts using velocity, graph anomalies, and device fingerprints.
- Down-rank suspicious content in ranking models.
- Rate-limit follow/like/comment actions by account trust tier.
- Route high-risk actions to moderation queues.
This preserves ranking quality and prevents engagement fraud from dominating recommendations.
Conclusion
Designing Instagram’s feed combines high-throughput write challenges with low-latency read requirements. The key takeaways are:
- Fan-out on Write is efficient for most users.
- Hybrid Model handles celebrities.
- Redis is essential for the “Feed” data structure.
- Async Processing using queues keeps the system responsive.
References
- Instagram Engineering Blog: Sharding IDs
- System Design Primer - Feed Architecture
- Facebook’s News Feed Architecture (InfoQ)
YouTube Videos
-
“Design Instagram - System Design Interview” - Exponent [https://www.youtube.com/watch?v=Y6Ev8GIlbxc]
-
“System Design Interview - Notification Service” - Gaurav Sen [https://www.youtube.com/watch?v=bBTPZ9NdSk8]