Designing a news feed like Twitter (or X) is a classic system design interview question. It tests your ability to handle massive scale, write-heavy vs. read-heavy workloads, and complex fanout operations. This guide covers the “Hybrid Approach” often expected by interviewers at top tech companies.
Need a quick revision before interviews? Read the companion cheat sheet: System Design Interview: Twitter News Feed System Design CheatSheet.
Table of Contents
Open Table of Contents
- Interview Framework: How to Approach This Problem
- Step 1: Clarifying Requirements
- Step 2: Core Assumptions and Constraints
- Step 3: High-Level Architecture
- Step 4: The Hardest Problem - Timeline Fanout
- Step 5: Key Technical Decision - Push vs Pull vs Hybrid
- Step 6: Database Design and Storage
- Step 7: Scaling the System
- Step 8: Security and Permissions
- Step 9: Handling Edge Cases
- Step 10: Performance Optimizations
- Real-World Implementations
- Common Interview Follow-Up Questions
- Conclusion
- References
- YouTube Videos
Interview Framework: How to Approach This Problem
In a system design interview, when asked to design Twitter, here’s the structured approach you should follow:
- Clarify requirements (5 minutes) - Identify if we are focusing on the Home Timeline, User Timeline, or Search.
- State assumptions (2 minutes) - Define the scale (e.g., 300M DAU).
- High-level design (10 minutes) - Sketch the API gateway, services, and storage.
- Deep dive (20 minutes) - Focus on the Fanout Service (this is the heart of Twitter).
- Scale and optimize (10 minutes) - Discuss caching strategies (Redis) and Hybrid Fanout.
- Edge cases (3 minutes) - Celebrity accounts (Justin Bieber problem).
Key mindset: Don’t just design for “now”. Design for the read/write imbalance (reads >> writes).
Step 1: Clarifying Requirements
Questions to Ask the Interviewer
Q: Are we focusing on the Home Timeline or User Timeline?
- Interviewer: Focus on the Home Timeline (aggregating tweets from people you follow).
Q: Does the timeline include retweets, replies, and media?
- Interviewer: Yes, for now assume text and images.
Q: How fast should a new tweet appear in a follower’s feed?
- Interviewer: Near real-time. Within 5 seconds ideally.
Q: Do we need to support editing tweets?
- Interviewer: No, tweets are immutable for this exercise.
Functional Requirements
- Post Tweet: User can post a tweet (text/image).
- Home Timeline: User can view a scrollable list of tweets from followees.
- Follow: User can follow/unfollow others.
Non-Functional Requirements
- High Availability: The system should be always available (Eventual consistency is acceptable for timelines).
- Low Latency: 200ms latency for generating a timeline.
- Read Heavy: The read load is roughly 100x the write load.
Step 2: Core Assumptions and Constraints
To design effectively, we need concrete numbers.
- DAU (Daily Active Users): 300 Million.
- Tweets per day: 500 Million (approx 6k tweets/sec).
- Timeline Views: 20 Billion per day (approx 230k req/sec).
- Read:Write Ratio: ~100:1.
- Followers: Average user has ~200 followers. “Whales” (celebrities) have millions.
Constraint: The system must handle the “Celebrity Problem” (one tweet triggering millions of feed updates).
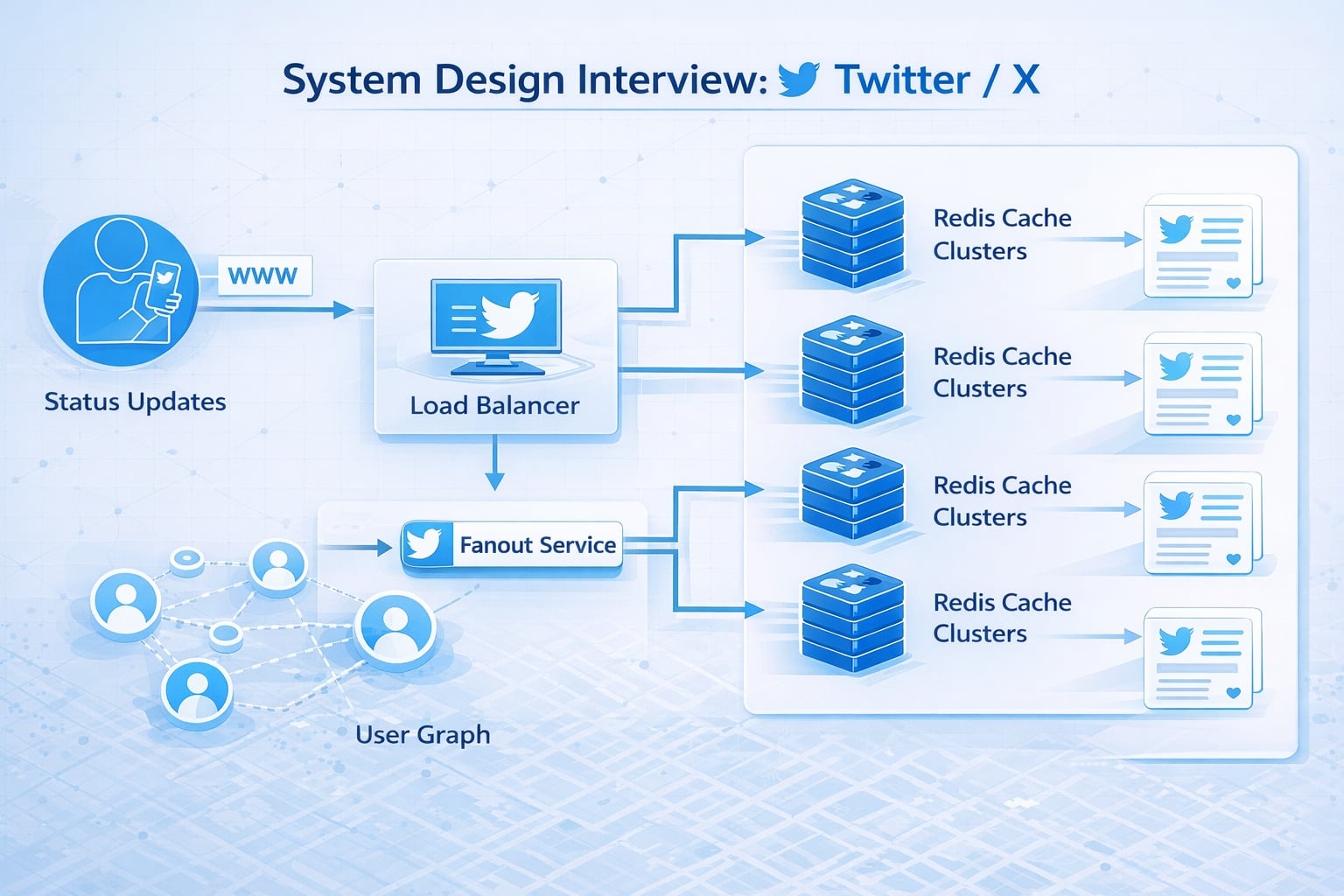
Step 3: High-Level Architecture
“Let me start with a high-level architecture. We’ll separate the Write Path (Posting) from the Read Path (Reading).”
System Flow Diagram
flowchart TD
User[Client] --> LB[Load Balancer]
LB --> API[API Gateway]
API -- Post Tweet --> TweetSvc[Tweet Service]
API -- Get Timeline --> FeedSvc[Timeline Service]
API -- Follow --> GraphSvc[User Graph Service]
TweetSvc --> Cache[(Tweet Cache)]
TweetSvc --> DB[(Tweet DB)]
TweetSvc --> Fanout[Fanout Service]
Fanout --> GraphSvc
Fanout --> RCache[(Redis Timeline Cache)]
FeedSvc --> RCache
FeedSvc --> CacheData Flow
- Write Path: User posts a tweet via
Tweet Service. It is saved to DB/Cache. - Fanout:
Tweet ServicetriggersFanout Service. - Fanout Logic:
Fanout Servicefetches followers fromGraph Serviceand injects the Tweet ID into each follower’s “Home Timeline” list in Redis. - Read Path: User requests timeline.
Timeline Servicefetches the pre-computed list of Tweet IDs from Redis, then hydrates them with content fromTweet Cache.
Why This Architecture?
- Decoupled Write/Read: Writing happens asynchronously (fanout). Reading is just fetching a pre-built list (O(1)).
- Key Insight: We optimize for the read path because it happens 100x more often.
Step 4: The Hardest Problem - Timeline Fanout
The core challenge of Twitter is distribution. When user A tweets, it must appear in the feeds of all 1,000 followers.
The Complexity
If User A has 1 million followers, a single write triggers 1 million updates.
If we do this synchronously, the write api will time out.
If we query the DB on load (SELECT * FROM tweets WHERE user_id IN (following_list)), the DB will die under join load.
We need Fanout-on-Write (Push Model).
Step 5: Key Technical Decision - Push vs Pull vs Hybrid
“This is the most critical decision in the interview. Let’s compare approaches.”
Approach 1: Pull Model (Fanout-on-Read)
- How: Store tweets. On read, query DB for all followees, merge, sort, return.
- Pros: Simple writes. No “celebrity problem”.
- Cons: Terrible read latency. DB struggle with expensive joins.
- Verdict: ❌ Too slow for 300M DAU.
Approach 2: Push Model (Fanout-on-Write)
- How: maintain a pre-computed “Timeline List” for every user in Redis. When X tweets, append Tweet ID to lists of all X’s followers.
- Pros: Lightning fast reads (O(1)).
- Cons: “Justin Bieber Problem”. Writing to 100M timeline lists takes too long.
- Verdict: ❌ Fails for celebrities.
Approach 3: Hybrid Approach (The Win!)
- How:
- Normal Users: Use Push Model.
- Celebrities/Whales: Use Pull Model.
- Logic: When a normal user tweets, push to all followers. When Bieber tweets, don’t push.
- Read Time: When I load my feed, the system fetches my pre-computed list (pushed tweets) AND queries the tweets of celebrities I follow (pull), then merges them.
- Verdict: ✅ Best of both worlds.
Step 6: Database Design and Storage
Data Classification
- User Data/Auth: SQL (MySQL/PostgreSQL) - Strong consistency needed.
- Social Graph (Follows): SQL or Graph DB (Neo4j/TAO). TAO (Facebook’s creation) is ideal here.
- Tweets: NoSQL (Cassandra/DynamoDB). High write throughput, simple KV access.
- Timelines: Redis. List of Tweet IDs.
Schema Design (Simplified)
Tweet Table (Cassandra)
timestamp | tweet_id | user_id | content | media_url
PK: (user_id, timestamp) -- Clustered by time for fast retrievalTimeline Cache (Redis)
Key: user_id_timeline
Value: List[tweet_id_1, tweet_id_2, tweet_id_3...]Step 7: Scaling the System
Bottleneck 1: Redis Memory
- Problem: Storing timelines for 300M users is expensive.
- Solution: Only store the last 800 tweet IDs. Older tweets are fetched via DB fallback (Pull) if the user scrolls that far.
Bottleneck 2: Tweet ID Generation
- Problem: We need globally unique, time-sortable IDs faster than DB auto-increment.
- Solution: Snowflake ID (Twitter’s own invention).
- 64-bit integer: 41 bits timestamp, 10 bits machine ID, 12 bits sequence.
- Allows sorting by ID to equal sorting by time.
Capacity Planning
- Storage: 500M tweets * 200 bytes = 100GB/day = 36TB/year. manageable.
- Media: Stored in S3/CDN. Only metadata in DB.
Step 8: Security and Permissions
“We need to ensure users only see content allowed.”
Private Accounts
If a user is private, the Fanout service must check is_approved_follower.
In the Hybrid model, private tweets are rarely pushed to public caches without strict ACLs.
Authentication
Start with OAuth 2.0 / JWT for API handling.
Step 9: Handling Edge Cases
Edge Case 1: The “Unfollow” Event
Scenario: User A unfollows User B. Handling: Asynchronously remove B’s tweets from A’s Redis list. This is expensive, so we might just filter them out at Read time for a while until the cache expires.
Edge Case 2: Viral Retweets
Scenario: A tweet gets 1M retweets in minutes. Handling: Cache the tweet object heavily (CDN + Local Cache) to prevent hot partitions in the Tweet DB.
Step 10: Performance Optimizations
- Pagination: Use
max_id(cursor-based pagination) instead ofoffset. Offset is slow in SQL. - CDN: Cache images and videos at the edge (Cloudflare/Akamai).
- Compression: Compress text logic before storage (though tweets are short, metadata adds up).
Real-World Implementations
Twitter (X)
- Originally Ruby on Rails, moved to Scala (Finagle).
- Uses Fanout-on-Write for most.
- Invented Snowflake for IDs.
- Uses Manhattan (internal NoSQL) and Redis clusters.
Facebook News Feed
- Uses a darker version of Hybrid (mostly Pull with smart ranking).
- TAO (The Association Object) for graph data.
Common Interview Follow-Up Questions
Q: How do you handle searching tweets?
Answer: “Search should be a separate read-optimized system:
- Write tweets to primary Tweet DB first.
- Publish async indexing events to a search pipeline.
- Index in Elasticsearch/OpenSearch with language analyzers and hashtag/mention fields.
- Accept a short indexing delay (eventual consistency) to keep write latency low.
Trade-off: Slight search lag is acceptable; coupling search in the write path is not.”
Q: How to implement ‘Trends’?
Answer: “Use stream processing over engagement events:
- Ingest likes, retweets, replies, and hashtag usage into Kafka.
- Aggregate scores in sliding windows (for example 5, 15, 60 minutes).
- Normalize by region and baseline volume to avoid always-on popular tags.
- Apply anti-spam filters before publishing trend lists.
This catches fast-moving topics while limiting manipulation.”
Q: How do you handle celebrity accounts with massive fan-out?
Answer: “I use hybrid fan-out:
- Normal users: fan-out-on-write for fast timeline reads.
- Celebrity users: fan-out-on-read to avoid pushing to millions of inboxes instantly.
- Merge both sources in timeline service with ranking.
- Cache merged timelines for short TTL to reduce recomputation.
This controls write amplification without hurting read latency for most users.”
Q: How do you remove deleted tweets from cached home timelines?
Answer: “I treat delete as a high-priority invalidation event:
- Emit tombstone event when tweet is deleted or moderated.
- Remove tweet ID from timeline cache indexes.
- Enforce final read-time filter against authoritative tweet status.
- Run periodic cache repair jobs for missed invalidations.
This prevents stale or policy-violating content from lingering in feeds.”
Q: How would you support “Following” (chronological) and “For You” (ranked) feeds?
Answer: “I’d split the serving paths but reuse shared storage:
- Following feed: timeline merge sorted by timestamp.
- For You feed: candidate generation + ML ranking + business rules.
- Share safety filters, user graph, and tweet metadata between both paths.
- Expose separate caching policies per tab.
Trade-off: Two pipelines increase complexity, but product flexibility and experimentation improve significantly.”
Conclusion
Designing Twitter is about managing distribution. The Hybrid Fanout pattern is the gold standard answer. By mixing Push for normal users and Pull for celebrities, we balance write load and read latency.
Key Takeaways:
- Read-heavy system (optimize for reads).
- Fanout-on-write is great, but fails for celebrities.
- Hybrid approach solves the scale issue.
- Snowflake IDs are crucial for sorting.
References
YouTube Videos
- “How to Answer System Design Interview Questions” - Exponent [https://www.youtube.com/watch?v=NtMvNh0WFVM]
- “Design Twitter - System Design Interview” - Gaurav Sen [https://www.youtube.com/watch?v=wYk0xPP_P_8]