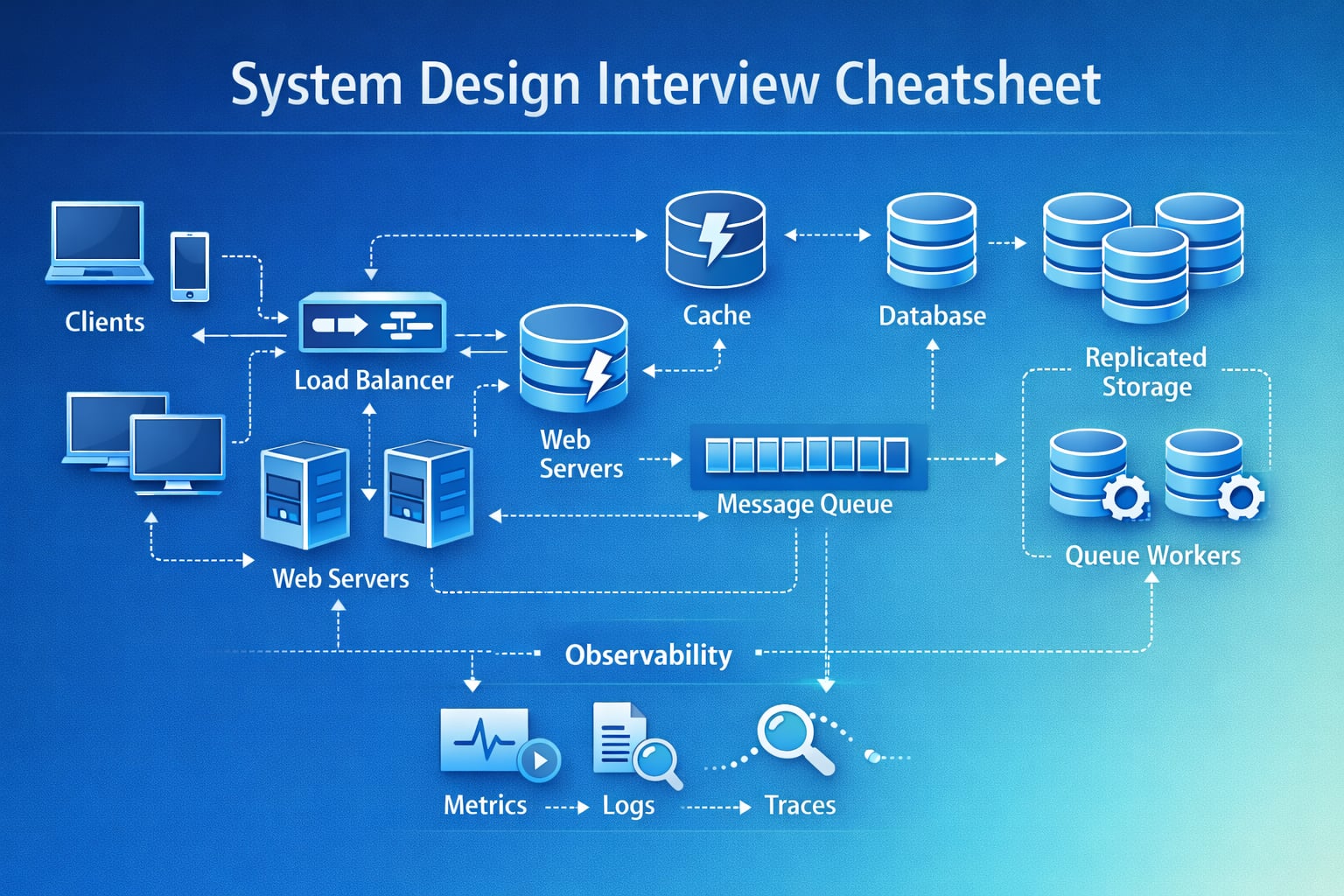
This is a practical system design interview cheatsheet you can use for almost any prompt: feed, chat, storage, search, or marketplace. It gives you a structured way to clarify requirements, make trade-offs, do quick capacity math, and communicate like a senior engineer in the interview.
Table of Contents
Open Table of Contents
- Interview Framework: How to Approach This Problem
- Step 1: Clarifying Requirements
- Step 2: Core Assumptions and Constraints
- Step 3: High-Level Architecture
- Step 4: The Hardest Problem - Choosing the Primary Bottleneck
- Step 5: Key Technical Decision - Consistency vs Latency
- Step 6: Database Design and Storage
- Step 7: Scaling the System
- Step 8: Security and Permissions
- Step 9: Handling Edge Cases
- Step 10: Performance Optimizations
- Real-World Implementations
- Common Interview Follow-Up Questions
- Q1: How would you redesign this for 10x traffic next year?
- Q2: What if the interviewer asks for strict consistency globally?
- Q3: How would you handle schema evolution without downtime?
- Q4: What metrics do you monitor first in production?
- Q5: How do you reduce cloud cost by 30 percent without hurting SLO?
- Q6: How do you prevent duplicate side effects in retries?
- Conclusion
- References
- YouTube Videos
Interview Framework: How to Approach This Problem
In a system design interview, when asked to design any large system, use this repeatable approach:
- Clarify requirements (5 minutes) - Ask questions first, do not jump to architecture.
- State assumptions (2 minutes) - Convert vague scope into concrete numbers.
- High-level design (10 minutes) - Draw the major services and data flow.
- Deep dive (20 minutes) - Pick the hardest bottleneck and solve it thoroughly.
- Scale and optimize (10 minutes) - Show capacity math, bottlenecks, and trade-offs.
- Edge cases and security (3 minutes) - Prove production readiness.
Key mindset: Think out loud. The interviewer is grading your decision-making quality, not your diagram beauty.
Step 1: Clarifying Requirements
“Before designing, let me confirm scope and success criteria.”
Questions to Ask the Interviewer
Q: What exact user journey should we optimize first?
- Assumption: Design for the core read/write path first, not all features.
Q: What is the target scale?
- Assumption: 50 million total users, 5 million daily active users (DAU), and 500,000 concurrent users at peak.
Q: What latency target matters most?
- Assumption: 95th percentile (P95) read latency under 200 ms, write acknowledgment under 300 ms.
Q: Do we need strong consistency or is eventual consistency acceptable?
- Assumption: Eventual consistency is acceptable for most reads, strict correctness for payments/auth.
Q: Multi-region from day one or single region first?
- Assumption: Start single-region, design interfaces for multi-region expansion.
Q: How much data retention is required?
- Assumption: 90 days hot, 1 year warm, long-term cold archive.
Q: Any compliance/security requirements?
- Assumption: General Data Protection Regulation (GDPR)-style delete, audit logs, encryption in transit and at rest.
Q: What is out of scope for the minimum viable product (MVP)?
- Assumption: Advanced analytics and machine learning (ML) ranking can be phase 2.
Functional Requirements
Based on those answers, this generic interview-ready system should support:
- User authentication and authorization.
- Core write operation (create/update action).
- Core read operation with pagination.
- Asynchronous processing for side effects (notifications, indexing, analytics).
- Basic search/filter capability.
- Admin/debug capabilities (status and audit trail).
- Retry-safe application programming interfaces (APIs) using idempotency.
Non-Functional Requirements
- Availability: 99.9 percent for MVP, higher for critical domains.
- Latency: P95 under 200 ms for reads, under 300 ms for writes.
- Scalability: 10x growth without full redesign.
- Durability: No data loss for committed writes.
- Security: Least privilege, encrypted transport/storage, auditability.
- Cost efficiency: Predictable unit cost as traffic scales.
Step 2: Core Assumptions and Constraints
“I will state concrete assumptions so my architecture decisions are measurable.”
Traffic Assumptions
Total users: 50,000,000
DAU: 5,000,000
Peak concurrent users: 500,000
Average read actions per active user per day: 40
Average write actions per active user per day: 4
Read:Write ratio: 10:1Quick Capacity Math Cheatsheet
Use these formulas live in interviews. Here, queries per second (QPS) is the most important throughput metric:
queries per second (QPS) = (users x actions_per_day) / 86,400
Peak QPS = average QPS x peak_factor (usually 3 to 5)
Storage/day = writes_per_day x avg_record_size
Bandwidth/sec = requests_per_sec x avg_payload_sizeExample Back-of-the-Envelope
Reads/day = 5,000,000 x 40 = 200,000,000
Average read QPS = 200,000,000 / 86,400 = ~2,315
Peak read QPS (x4) = ~9,260
Writes/day = 5,000,000 x 4 = 20,000,000
Average write QPS = 20,000,000 / 86,400 = ~231
Peak write QPS (x4) = ~924
If write payload is 1 KB:
Daily write storage = 20,000,000 KB = ~19 GB/day
With 3x replication = ~57 GB/dayInterview Constraint Checklist
- Latency target by endpoint.
- Availability target by tier.
- Consistency expectations.
- Legal/compliance constraints.
- Budget and timeline constraints.
Step 3: High-Level Architecture
“Let me start with a high-level design and then we can deep dive into the hardest bottleneck.”
System Flow Diagram
flowchart TD
A[Client Apps] --> B[CDN - Content Delivery Network; WAF - Web Application Firewall]
B --> C[API Gateway - Application Programming Interface]
C --> D[Auth Service]
C --> E[Read Service]
C --> F[Write Service]
E --> G[(Cache)]
E --> H[(Primary DB - Database)]
F --> H
F --> I[Message Queue]
I --> J[Async Workers]
J --> K[(Search Index)]
J --> L[(Analytics Store)]
J --> M[Notification Service]Walking Through the Data Flow
- Client sends authenticated request through the content delivery network (CDN) and web application firewall (WAF).
- The application programming interface (API) gateway validates the token and applies rate limits.
- Read requests hit cache first, then the primary database (DB) on misses.
- Write requests commit to the primary DB using idempotency keys.
- Write service emits events to queue for async side effects.
- Workers consume events and update search, analytics, and notifications.
- Observability pipeline tracks latency, error rate, and queue lag.
Why This Architecture?
- Decouples user-facing latency from heavy background work.
- Optimizes the read path using cache because reads dominate traffic.
- Keeps the write path reliable with durable DB commit before async fanout.
- Supports independent scaling of read, write, and worker tiers.
Step 4: The Hardest Problem - Choosing the Primary Bottleneck
“The common interview mistake is trying to optimize everything at once. The right move is to identify the single dominant bottleneck first.”
The Core Problem
At scale, systems fail because one resource saturates first: database input/output operations per second (IOPS), cache miss storms, queue backlog, or network egress.
Concrete scenario:
- API latency jumps from 180 ms to 2.5 s during peak.
- Team scales app servers 3x.
- Latency remains high because database connection pool is exhausted.
Approach 1: Horizontal Scale Everything
Add more service replicas everywhere.
Problem: Expensive and often does not fix the root constraint.
Verdict: Not reliable.Approach 2: Optimize Based on Guessing
Tune random queries and add caches without measurements.
Problem: You may optimize the wrong path and waste interview time.
Verdict: Weak engineering process.Approach 3: Bottleneck-First Strategy (Recommended)
1. Measure: p95 latency by dependency.
2. Rank bottlenecks by impact and blast radius.
3. Fix top bottleneck.
4. Re-measure and iterate.
Verdict: Production-grade approach.Practical Decision Framework
type Bottleneck = {
name: string;
p95Ms: number;
trafficShare: number;
errorRate: number;
blastRadius: number;
};
function score(b: Bottleneck): number {
// Higher score means higher priority to fix.
return b.p95Ms * b.trafficShare * (1 + b.errorRate) * b.blastRadius;
}Interview phrasing: “I would first quantify dependency latency and error concentration, then prioritize the component with the highest user-impact score.”
Step 5: Key Technical Decision - Consistency vs Latency
“Most system design interviews eventually become a consistency trade-off discussion. I will choose consistency level by user impact.”
Option 1: Strong Consistency Everywhere
Pros: Always correct reads.
Cons: Higher latency, lower availability during partitions.
Use for: Payments, balances, permission changes.Option 2: Eventual Consistency Everywhere
Pros: Fast reads, high availability, easier geo-scale.
Cons: Stale reads and temporary anomalies.
Use for: Feeds, counters, analytics dashboards.Option 3: Hybrid Consistency (Recommended)
Strong consistency for critical writes.
Eventual consistency for derived/read-heavy data.
Add read-your-writes/session guarantees for user experience.Why Hybrid Usually Wins
- Keeps critical correctness where it matters.
- Preserves low latency on high-volume read paths.
- Reduces cross-region coordination overhead.
- Matches real-world architecture used by large consumer platforms.
Step 6: Database Design and Storage
“I will separate data by access pattern, not by team preference.”
Data Classification
- Hot data: Frequently read recent objects and session state.
- Storage: Redis or memory cache.
- Latency target: 1-5 ms.
- Warm data: Main transactional entities.
- Storage: PostgreSQL/MySQL (structured query language, SQL) or DynamoDB/Cassandra (not only SQL, NoSQL), depending on access shape.
- Latency target: 10-50 ms.
- Cold data: Historical logs, analytics, compliance archive.
- Storage: Object storage such as Amazon Simple Storage Service (S3) or Google Cloud Storage (GCS), plus a warehouse.
- Latency target: Minutes is acceptable.
Example Relational Schema
We use JavaScript Object Notation Binary (JSONB) columns for flexible payload fields.
CREATE TABLE entities (
entity_id BIGINT PRIMARY KEY,
owner_id BIGINT NOT NULL,
status VARCHAR(20) NOT NULL,
payload JSONB NOT NULL,
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL
);
CREATE INDEX idx_entities_owner_updated
ON entities(owner_id, updated_at DESC);Example Event Table for Async Processing
Use a universally unique identifier (UUID) for event_id to support deduplication across services.
CREATE TABLE outbox_events (
event_id UUID PRIMARY KEY,
aggregate_id BIGINT NOT NULL,
event_type VARCHAR(50) NOT NULL,
payload JSONB NOT NULL,
created_at TIMESTAMP NOT NULL,
published BOOLEAN NOT NULL DEFAULT FALSE
);
CREATE INDEX idx_outbox_unpublished
ON outbox_events(published, created_at);Storage Tier Strategy
- Keep only last 30-90 days in hot/warm stores.
- Move older immutable data to cheap object storage.
- Build replay tooling to reprocess archived events when needed.
Step 7: Scaling the System
“Now I will identify bottlenecks and map each one to a concrete scaling strategy.”
Bottleneck 1: Database Hot Partitions
Problem: One shard gets most writes due to skewed keys.
Solution:
- Use high-cardinality partition keys.
- Introduce key bucketing for hot tenants.
- Add write-through cache only for idempotent read patterns.
Bottleneck 2: Cache Stampede
Problem: Popular key expires, thousands of requests hit DB at once.
Solution:
- Use request coalescing/single-flight.
- Add jitter to time to live (TTL).
- Serve stale-while-revalidate for short window.
Bottleneck 3: Queue Backlog Growth
Problem: Worker throughput falls below event ingress.
Solution:
- Autoscale workers based on queue lag.
- Split heavy and light jobs into separate queues.
- Apply dead-letter queues and retry backoff policies.
Bottleneck 4: Multi-Region Latency
Problem: Cross-region round trips break latency service level objective (SLO).
Solution:
- Route users to nearest read region.
- Replicate data asynchronously for non-critical reads.
- Keep strong consistency only for critical domains.
Capacity Planning Example
Assumptions:
- Peak read QPS: 10,000
- Peak write QPS: 1,000
- One read-service instance handles 800 QPS
- One write-service instance handles 150 QPS
Read instances needed = 10,000 / 800 = 13
With 40% headroom: 19
Write instances needed = 1,000 / 150 = 7
With 40% headroom: 10
If one cache node handles 120,000 ops/sec:
Cache nodes needed for 10,000 reads/sec with replication and headroom: 3-4 nodes minimumGeographic Distribution Strategy
- Start single region with clear failover playbook.
- Move to active-active reads across regions.
- Keep writes region-local where possible.
- Add conflict resolution strategy before global active-active writes.
Step 8: Security and Permissions
“Security should be designed into the architecture, not bolted on after scaling.”
Permission Model
const PERMISSIONS = {
OWNER: ["read", "write", "delete", "share", "admin"],
EDITOR: ["read", "write"],
VIEWER: ["read"],
};Auth and Authorization Flow
- API Gateway validates JSON Web Token (JWT) and tenant context.
- Service-level policy check validates role + resource ownership.
- Sensitive actions require re-auth or stronger token scope.
- All policy decisions are logged for audit.
Share Link and Public Access Pattern
- Signed uniform resource locators (URLs) with expiration and scoped permissions.
- Revocation list for emergency disable.
- Rate-limited access to prevent scraping.
WebSocket or Streaming Security
- Authenticate before connection upgrade.
- Revalidate token on reconnect and rotation intervals.
- Enforce per-connection quotas.
- Close channels on permission updates.
Step 9: Handling Edge Cases
“Let me cover the failure modes interviewers usually ask about.”
Edge Case 1: Region Outage
Scenario: Primary region fails during peak traffic.
Approach:
- Health checks trigger failover.
- Domain Name System (DNS)/load balancer shifts read traffic to secondary.
- Critical writes use degraded mode with strict rate limits.
- Backfill missing writes after recovery.
Edge Case 2: Duplicate Event Delivery
Scenario: Queue delivers message more than once.
Approach:
- Make consumers idempotent using
event_id. - Keep dedupe window in Redis/DB.
- Ignore already-processed events safely.
Edge Case 3: Out-of-Order Updates
Scenario: Older event arrives after newer event.
Approach:
- Use version numbers or logical timestamps.
- Reject stale writes at storage layer.
- Emit reconciliation jobs for detected divergence.
Edge Case 4: Thundering Herd After Cache Flush
Scenario: Deployment clears hot cache.
Approach:
- Stagger cache warmup.
- Enforce single-flight on misses.
- Protect DB with temporary per-key rate limits.
Edge Case 5: Poison Messages in Queue
Scenario: One malformed event keeps failing and blocks progress.
Approach:
- Retry with capped exponential backoff.
- Move persistent failures to dead-letter queue (DLQ).
- Alert and provide replay tooling after fix.
Step 10: Performance Optimizations
“After correctness and reliability, I optimize the top latency and cost drivers.”
1. Multi-Layer Caching
L1: Client/browser cache
L2: CDN edge cache
L3: Service memory cache
L4: Redis distributed cache
L5: DatabaseImpact: 60-90 percent reduction in DB read load when cache keys are designed well.
2. Request Coalescing and Batching
- Combine duplicate in-flight reads for same key.
- Batch writes/events to reduce network and storage overhead.
Impact: Lower p95 latency and improved throughput under burst traffic.
3. Data Access Shaping
- Cursor-based pagination instead of offset scans.
- Projection queries to fetch only required fields.
- Avoid N+1 calls by prefetching related data.
Impact: Significant central processing unit (CPU) and query time reduction at high cardinality.
4. Compression and Serialization Choices
- Use compact payloads for internal APIs.
- Compress large responses over network.
- Keep schema compatibility with versioned contracts.
Impact: Lower bandwidth cost and faster cross-region transfers.
Real-World Implementations
Google-Style SLO-Driven Architecture
What they use:
- Service level objective (SLO) and service level agreement (SLA)-based engineering, strong observability culture, and globally distributed infrastructure.
- Mix of strongly consistent systems for critical data and eventually consistent systems for derived products.
Scale signal:
- Publicly discussed internet-scale workloads and global traffic distribution.
Key idea to reuse in interviews:
- Start with SLOs and error budgets, then choose architecture.
Netflix Platform Patterns
What they use:
- Microservices, heavy caching, event streaming, and resilience testing.
- Separation of control planes and data planes for reliability.
Scale signal:
- Publicly reported hundreds of millions of subscribers and global streaming delivery.
Key idea to reuse in interviews:
- Decouple synchronous user flows from async workflows using queues/events.
Amazon-Style Cell and Queue-Centric Design
What they use:
- Queue-based decoupling, multi-availability-zone (multi-AZ) deployment, and cell-based isolation.
- Managed databases and storage with strict operational metrics.
Scale signal:
- High-traffic commerce events with large seasonal spikes.
Key idea to reuse in interviews:
- Isolate blast radius with cells and design graceful degradation paths.
Common Interview Follow-Up Questions
Q1: How would you redesign this for 10x traffic next year?
Answer: “I would scale by bottleneck, not by assumption:
- Profile current saturation points (DB, cache, queue, network).
- Move expensive sync side effects to async pipeline.
- Introduce partitioning and regional read replicas.
- Add aggressive caching plus request coalescing.
Trade-off: More distributed components increase ops complexity, but they avoid a full rewrite.”
Q2: What if the interviewer asks for strict consistency globally?
Answer: “I would push back on latency expectations and present options:
- Use strongly consistent primary region for critical writes.
- Accept higher write latency due to cross-region quorum.
- Keep non-critical reads eventually consistent.
- Reserve global strict mode only for small, critical domains.
Trade-off: Strong consistency improves correctness guarantees but reduces availability and speed during partitions.”
Q3: How would you handle schema evolution without downtime?
Answer: “I would use backward-compatible rollout:
- Add new fields as optional.
- Deploy readers that tolerate old and new schema.
- Deploy writers that emit both old/new when needed.
- Backfill in batches, then remove legacy fields.
Trade-off: Temporary dual-write complexity, but zero downtime and safe rollback.”
Q4: What metrics do you monitor first in production?
Answer: “I monitor user-impact metrics before infra vanity metrics:
- 95th percentile (P95) and 99th percentile (P99) latency by endpoint.
- Error rate by dependency and status class.
- Queue lag and retry/DLQ volume.
- Cache hit ratio and DB saturation.
- Cost per 1,000 requests.
Trade-off: More observability overhead, but faster root-cause analysis and better incident response.”
Q5: How do you reduce cloud cost by 30 percent without hurting SLO?
Answer: “I would optimize hot paths and data lifecycle:
- Increase cache hit ratio and right-size TTLs.
- Shift old data from warm DB to object storage.
- Use autoscaling based on real utilization, not static peaks.
- Batch async jobs and compress payloads.
Trade-off: More tuning and governance work, but sustainable unit economics.”
Q6: How do you prevent duplicate side effects in retries?
Answer: “I design idempotency end-to-end:
- Require client idempotency keys for writes.
- Persist processed event IDs with TTL window.
- Make consumers upsert-safe and side-effect aware.
- Replay with dedupe checks.
Trade-off: Extra storage and logic, but critical for correctness in at-least-once pipelines.”
Conclusion
If you remember one rule for system design interviews, remember this: clarify first, quantify second, then design by bottleneck.
Key Takeaways
- Use a fixed interview structure so you never get lost.
- Convert vague requirements into numbers quickly.
- Separate read and write paths to scale independently.
- Pick consistency level based on business criticality.
- Design for failure, retries, and observability from day one.
- Explain trade-offs explicitly in every major decision.
Recommended Baseline Stack (Interview-Friendly)
- API Gateway + stateless services
- Redis for hot reads
- SQL/NoSQL selected by access pattern
- Queue + workers for async workflows
- Metrics, logs, traces, alerts, and runbooks
References
- Designing Data-Intensive Applications - Martin Kleppmann
- Google Site Reliability Engineering (SRE) Book
- Amazon Web Services (AWS) Well-Architected Framework
- Google Spanner Paper
- Meta Engineering: TAO - The Power of the Graph
- Kafka Documentation
- The Dynamo Paper
YouTube Videos
- “System Design Interview: A Framework for Beginners and Seniors” - ByteByteGo [https://www.youtube.com/watch?v=bUHFg8CZFws]
- “How to Answer System Design Interview Questions” - Exponent [https://www.youtube.com/watch?v=NtMvNh0WFVM]
- “Design a URL Shortener - System Design Interview” - Gaurav Sen [https://www.youtube.com/watch?v=JQDHz72OA3c]
- “Distributed Systems in One Lesson” - Hussein Nasser [https://www.youtube.com/watch?v=Y6Ev8GIlbxc]
- “System Design Interview - Rate Limiter” - ByteByteGo [https://www.youtube.com/watch?v=FU4WlwfS3G0]
- “Microservices Communication Patterns” - IBM Technology [https://www.youtube.com/watch?v=xDuwrtwYHu8]