Your checkout request finished in 180ms, but the user still needs a receipt email, inventory sync, fraud check, analytics event, and maybe a PDF invoice. If the API waits for all of that to finish before returning a response, one slow dependency can make the whole user experience feel broken.
A message queue fixes this by letting your application hand off work to be processed later by another service or worker. The request stays fast, the heavy work still happens, and temporary failures become easier to absorb.
This guide explains what a message queue is, how it works, and when to use one in real backend systems. If you are following the learning path, read What Is Scalability? A Beginner’s Guide for Developers, How APIs Work: A Simple Guide for Beginners, and Monolith vs Microservices: Pros, Cons, and When to Choose first. For the broader roadmap, use the Practical Backend Engineering series as the pillar page and the Backend tag as a category page.
Table of Contents
Open Table of Contents
- What Is a Message Queue?
- Why Synchronous Calls Are Not Always Enough
- How a Message Queue Works
- Core Concepts: Producer, Consumer, Broker, and Ack
- Retries, Dead-Letter Queues, and Delivery Guarantees
- Message Queue vs Pub/Sub
- Common Use Cases
- A Practical Example: Processing Orders Asynchronously
- Real-World Examples
- Common Mistakes
- Interview Questions
- 1. What is a message queue and why is it useful?
- 2. What is the difference between a message queue and pub/sub?
- 3. Why do message queues often require idempotent consumers?
- 4. When should you avoid adding a message queue?
- 5. What metrics matter for queue-based systems?
- 6. Why not just call another service directly instead of using a queue?
- Conclusion
- References
- YouTube Videos
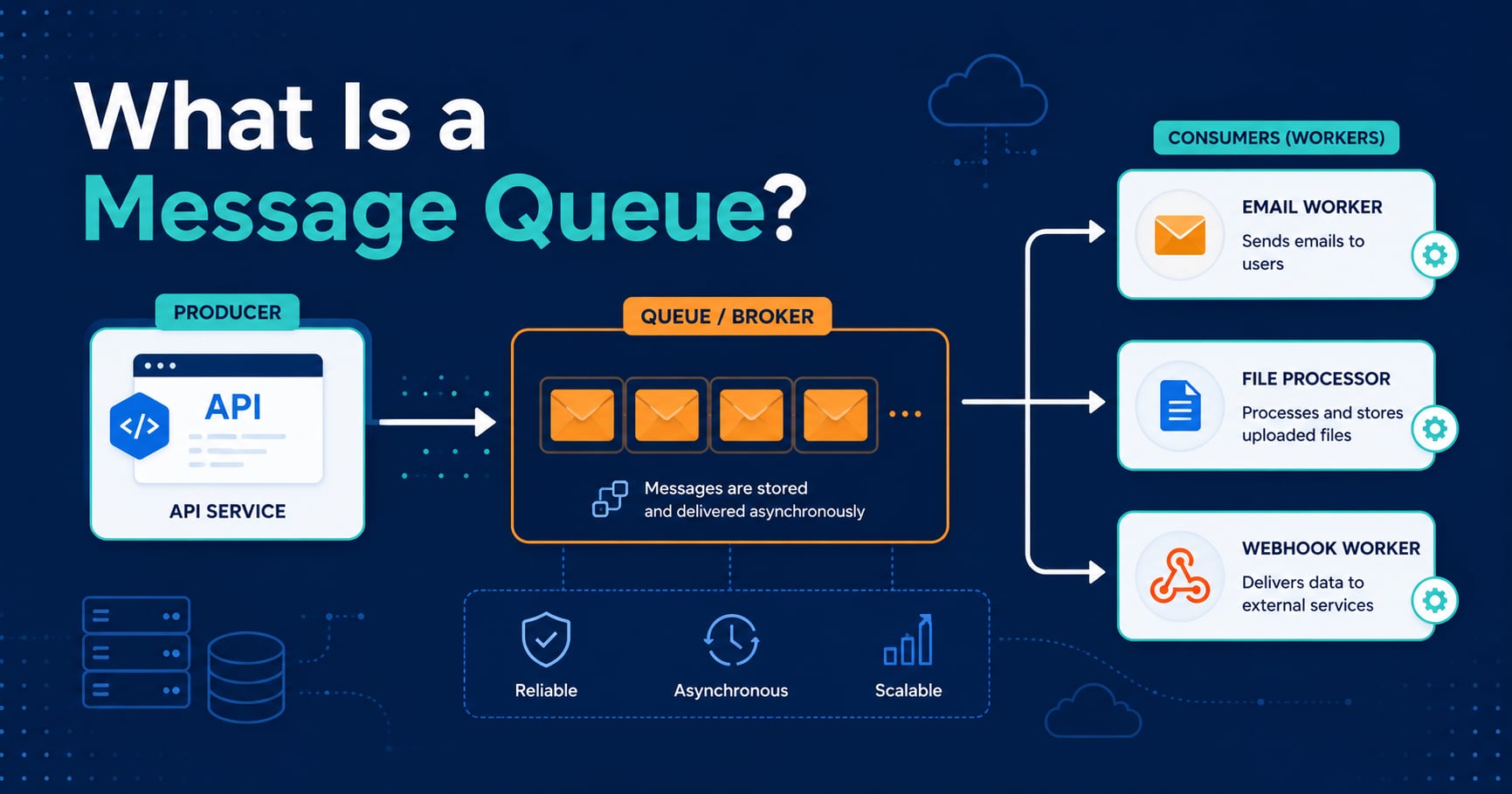
What Is a Message Queue?
A message queue is a software component that stores messages until another part of the system is ready to process them. One service produces a message, the queue holds it safely, and a consumer processes it later.
That sounds simple, but it changes system behavior in an important way: the producer and consumer no longer need to be available at the same time.
In a direct API call, Service A sends a request to Service B and waits for an answer right now. In a queue-based flow, Service A sends a message and can continue immediately. Service B, or a background worker owned by Service B, can pick up the message a little later.
The message usually contains data such as:
- an order ID
- a user ID
- an email payload
- a file path to process
- a command like
generateInvoice
The key idea is not “store data forever.” The key idea is “buffer work between producers and consumers.”
Why Synchronous Calls Are Not Always Enough
Direct synchronous calls are great when the user is actively waiting for the result. If you log in, you want the authentication answer immediately. If you request a product page, you need the product data now.
But many backend tasks are not truly user-blocking:
- sending confirmation emails
- resizing uploaded images
- generating reports
- posting webhooks
- updating search indexes
If these tasks stay in the request path, you inherit every downstream slowdown. One email provider timeout can suddenly make checkout slow. One image-processing spike can cause request queues to grow at your API layer. This is the same kind of critical-path problem discussed in What Is Scalability? A Beginner’s Guide for Developers: too much synchronous work makes the system brittle under load.
A message queue helps because it separates two concerns:
- accepting the request
- processing the follow-up work
That separation improves latency, fault tolerance, and elasticity. Your API can keep acknowledging work quickly while workers scale independently based on queue depth.
How a Message Queue Works
At a high level, the flow looks like this:
flowchart TD
A[User Action] --> B[API Server]
B --> C[(Database)]
B --> D[Message Queue]
D --> E[Worker 1]
D --> F[Worker 2]
E --> G[Email Service]
F --> H[Image Processor]
E --> I[Ack]
F --> IHere is the same flow in plain English:
- The user submits a request, like placing an order.
- The API does the work that must happen immediately, such as validating input and saving the order.
- The API publishes a message like
order.createdto the queue. - A worker consumes that message later.
- The worker sends the email, updates analytics, or triggers another downstream action.
- After success, the worker acknowledges the message so it can be removed from the queue.
The queue acts as a buffer between “work was requested” and “work was completed.” That buffer matters during spikes. If 10,000 users place orders in one minute, the queue can absorb the burst while workers drain it at a sustainable rate.
Core Concepts: Producer, Consumer, Broker, and Ack
There are a few terms that appear in every message-queue discussion.
Producer
The producer is the service that sends the message.
In an ecommerce app, the checkout service might publish order.created. In a file upload system, the upload API might publish image.uploaded.
The producer should usually do the minimum required work before publishing. It should not wait for every side effect to complete unless the user truly depends on those side effects.
Consumer
The consumer is the worker or service that reads messages from the queue and processes them.
Consumers are often scaled horizontally. If one worker can process 50 jobs per second and traffic grows, you can run more workers without changing the producer.
Broker
The broker is the queueing system itself, such as RabbitMQ, Amazon SQS, or Kafka-like infrastructure used for messaging patterns. It stores messages, manages delivery, and coordinates producers with consumers.
Different brokers have different trade-offs:
- RabbitMQ is popular for classic queue semantics and routing flexibility.
- Amazon SQS is a managed queue service that reduces operational overhead.
- Kafka is more event-stream oriented, but teams sometimes use it where they need durable asynchronous pipelines at very high scale.
Choosing a broker is an operational decision. Understanding the queue pattern matters more than memorizing one product.
Ack (Acknowledgment)
An acknowledgment tells the broker, “I processed this message successfully.”
This is one of the most important details. If a worker crashes after receiving a message but before finishing the job, the broker needs a way to know the work was not actually completed. That is why many systems remove a message only after the consumer explicitly acknowledges success.
Without acknowledgments, queueing loses much of its reliability value.
Retries, Dead-Letter Queues, and Delivery Guarantees
Once you add queues, you also need failure semantics. This is where beginner designs often get weak.
Retries
Some failures are temporary:
- email provider timeout
- downstream API rate limit
- short database outage
In these cases, retrying later is often correct. But retries must be controlled. Immediate blind retries can amplify an outage by hammering an already failing dependency.
The usual pattern is:
- try processing the message
- if it fails, retry with backoff
- after too many failures, move it elsewhere for inspection
Dead-Letter Queue
A dead-letter queue (DLQ) stores messages that repeatedly fail and should not be retried forever.
This matters because “retry forever” is not resilience. It is just hiding a stuck problem. A poisoned message can block progress, waste compute, and make the backlog harder to reason about.
flowchart TD
A[Consume Message] --> B{Processing Succeeds?}
B -- Yes --> C[Ack and Remove]
B -- No --> D{Retries Left?}
D -- Yes --> E[Requeue with Delay]
D -- No --> F[Move to Dead-Letter Queue]Delivery Guarantees
You will also hear these terms:
- At-most-once: the message is delivered zero or one time. Fast, but message loss is possible.
- At-least-once: the message is delivered one or more times. Reliable, but duplicates are possible.
- Exactly-once: the system guarantees one and only one successful delivery.
In practice, many production systems are at-least-once, which means your consumers should be idempotent. In other words, processing the same message twice should not charge the user twice or send the same invoice twice.
That is a critical mindset shift: queue reliability often comes from idempotent consumers plus retries, not from magical “exactly once everywhere” behavior.
Message Queue vs Pub/Sub
Beginners often mix up queues and pub/sub because both move messages between services.
The difference is about who receives a given message.
| Pattern | Who gets the message? | Good for |
|---|---|---|
| Message queue | One consumer processes a given message | Background jobs, task processing, order emails |
| Pub/Sub | Multiple subscribers each get their own copy | Event fanout, analytics, notifications to many systems |
With a queue, one order-email job should usually be handled by one worker. With pub/sub, an order.created event might go to analytics, billing, fraud detection, and notifications independently.
If you want the deeper interview version of queue-heavy architectures, System Design Interview: Notification System Design shows why asynchronous messaging is often non-negotiable at scale.
Common Use Cases
A message queue is valuable when work is important but does not need to finish before the HTTP response returns.
1. Sending emails and notifications
This is the classic first use case. Your API writes the main business record, publishes a message, and a worker sends the email later. If the email provider is slow for 30 seconds, your checkout API should still stay fast.
2. Background jobs
Generating reports, creating thumbnails, resizing images, exporting CSV files, and syncing third-party systems are all great queue candidates. These tasks are often expensive, bursty, or both.
3. Load smoothing
Queues absorb spikes. If 50,000 webhooks arrive in a short window, you may not have enough workers to process all of them immediately, but you can still accept them and drain the backlog safely.
4. Decoupling services
In a microservices environment, direct service-to-service dependencies can become fragile quickly. A queue allows Service A to say, “this work needs to happen,” without tightly coupling itself to the immediate availability of Service B.
5. Rate-limited integrations
If a partner API only allows 100 requests per second, a queue lets you throttle consumer throughput while still accepting incoming work upstream.
A Practical Example: Processing Orders Asynchronously
Consider an order placement flow.
The user needs these steps to happen before the request returns:
- validate the cart
- charge the payment
- persist the order
But the user does not need these steps to happen before the HTTP response returns:
- send confirmation email
- update CRM
- trigger loyalty-points workflow
This is where a queue belongs.
Producer example
import amqp from "amqplib";
const queueName = "order.created";
const connection = await amqp.connect("amqp://localhost");
const channel = await connection.createChannel();
await channel.assertQueue(queueName, { durable: true });
const message = {
orderId: "ord_123",
userId: "usr_42",
email: "ada@example.com",
};
channel.sendToQueue(queueName, Buffer.from(JSON.stringify(message)), {
persistent: true, // Ask the broker to persist the message instead of keeping it memory-only.
});
await channel.close();
await connection.close();Consumer example
import amqp from "amqplib";
const queueName = "order.created";
const connection = await amqp.connect("amqp://localhost");
const channel = await connection.createChannel();
await channel.assertQueue(queueName, { durable: true });
await channel.prefetch(1); // Limit each worker to one unacked job so slow jobs do not pile onto one worker.
channel.consume(queueName, async message => {
if (!message) return;
try {
const payload = JSON.parse(message.content.toString());
await sendOrderConfirmationEmail(payload);
channel.ack(message); // Ack only after the side effect succeeds.
} catch (error) {
channel.nack(message, false, true); // Requeue on transient failure; use DLQ policies in real systems.
}
});
async function sendOrderConfirmationEmail(payload) {
console.log(`Sending order confirmation for ${payload.orderId} to ${payload.email}`);
}What this example shows:
- the API and worker are decoupled
- the message is durable enough to survive normal process restarts when configured correctly
- the consumer acknowledges success explicitly
- failure handling is part of the design, not an afterthought
In real systems, you would also add:
- retry backoff
- idempotency keys
- structured logging
- metrics such as queue depth, retry count, and oldest-message age
Real-World Examples
Ecommerce checkout
An online store should not make checkout wait for email delivery, loyalty updates, and warehouse side effects. Those actions are natural background jobs. The queue keeps the order path responsive while workers process the rest.
File upload pipelines
When a user uploads an image or video, the first priority is storing the original file and returning success. Thumbnail generation, virus scanning, metadata extraction, and transcoding are all better handled asynchronously.
Webhook delivery
Systems that deliver webhooks to third-party clients must expect retries, timeouts, and endpoint failures. A queue provides controlled retries, DLQ handling, and a clear backlog when clients are slow.
Notification systems
Email, push, and SMS notifications are rarely safe to execute inline with the main user request. A queue makes it easier to route work to specialized workers and to scale those workers independently when traffic spikes.
Common Mistakes
1. Using a queue for work that must be immediately visible
If the user needs the answer right now, a queue is often the wrong abstraction. Authentication decisions, live balance checks, and synchronous validation usually belong in the request path.
2. Assuming queues guarantee exactly-once business behavior
Many systems guarantee message delivery, not business correctness. If your worker can process the same message twice, the application must be idempotent.
3. Retrying forever with no DLQ
Infinite retries turn permanent failures into invisible operational debt. Move poison messages into a DLQ and investigate them explicitly.
4. Not monitoring backlog growth
A healthy queue is not just “messages exist.” You need to know:
- queue depth
- age of oldest message
- retry volume
- consumer throughput
If backlog age keeps growing, your workers are under-provisioned or broken.
5. Treating Kafka, RabbitMQ, and SQS as interchangeable
They all move data asynchronously, but they are not identical. Ordering, retention, acknowledgment semantics, throughput patterns, and operating models differ. Start from the workload, then choose the tool.
Interview Questions
1. What is a message queue and why is it useful?
A message queue is a buffer between a producer and a consumer that allows work to be processed asynchronously instead of in the direct request path. It is useful because it reduces coupling between services, helps absorb traffic spikes, and keeps user-facing requests fast even when downstream work is slow. In practice, I explain that queues improve both latency and resilience: the producer does not need the consumer to be available at the exact same moment. The trade-off is additional operational complexity, especially around retries, duplicates, and monitoring.
2. What is the difference between a message queue and pub/sub?
A message queue usually means one consumer handles a given message, which makes it a good fit for task processing and background jobs. Pub/sub means multiple subscribers each receive a copy of the event, which is better for fanout scenarios like analytics, notifications, and audit pipelines. The key distinction is not the transport technology but the consumption model. When I answer this in interviews, I focus on whether the work is single-owner task execution or multi-subscriber event distribution.
3. Why do message queues often require idempotent consumers?
Most real queueing systems favor at-least-once delivery because it is safer to retry than to silently lose work. That means the same message can sometimes be delivered more than once, especially around worker crashes or acknowledgment timing. If the consumer is not idempotent, duplicate deliveries can create business bugs such as duplicate charges or repeated emails. Idempotency lets you keep the reliability benefits of retries without corrupting the system state.
4. When should you avoid adding a message queue?
You should avoid adding a queue when the caller truly needs the result before continuing, because asynchronous handoff would only add latency, complexity, and a harder debugging model. Queues are also a poor fit when the workload is tiny, operational simplicity matters more than future scale, or the team is not ready to monitor retries and backlogs properly. I usually say queues should be introduced to solve a clear reliability or throughput problem, not just because “microservices use messaging.” Premature queueing can turn a straightforward request flow into a distributed system for no real gain.
5. What metrics matter for queue-based systems?
The most important metrics are queue depth, oldest-message age, consumer throughput, retry count, and DLQ volume. Queue depth alone is not enough because a queue can be deep but still healthy if workers are draining it fast enough. Oldest-message age is often the better signal because it tells you whether users are experiencing delayed processing. I also want visibility into success rate per consumer and the time spent inside external dependencies, because queues often hide downstream slowness until the backlog becomes obvious.
6. Why not just call another service directly instead of using a queue?
Direct calls are simpler when the caller needs an immediate response and both services can tolerate being tightly coupled in time. A queue is better when the work can happen later, when downstream systems may be flaky, or when traffic arrives in bursts that need buffering. The decision is really about delivery semantics and failure isolation: direct calls fail in the request path, while queues move the work into a controlled asynchronous pipeline. That usually improves user-facing latency, but it also means you need good retry, idempotency, and observability discipline.
Conclusion
- A message queue is a buffer for asynchronous work, not just a place to “store messages.”
- Its main value is decoupling producers from consumers so user-facing requests stay fast and resilient.
- Retries, acknowledgments, idempotency, and dead-letter queues are core design concerns, not optional details.
- Queues are best for background jobs, burst smoothing, and unreliable downstream integrations.
- Choosing between direct calls, queues, and pub/sub depends on whether work is immediate, single-owner, or fanout-oriented.
The next topic in this series covers How Background Jobs Work in Web Applications and shows how workers, schedulers, and retries fit together on top of queue-based processing.
If you want to revisit the bigger architecture context, What Is Scalability? A Beginner’s Guide for Developers is the best companion post to read next.
References
-
What is a Message Queue? - AWS
https://aws.amazon.com/message-queue/ -
What is a message queue? - IBM
https://www.ibm.com/think/topics/message-queues -
Event-driven architecture with Pub/Sub - Google Cloud
https://cloud.google.com/solutions/event-driven-architecture-pubsub -
RabbitMQ Tutorials - RabbitMQ
https://www.rabbitmq.com/tutorials
YouTube Videos
-
“What is a MESSAGE QUEUE and Where is it used?“
https://www.youtube.com/watch?v=oUJbuFMyBDk -
“What are Messaging Queues? | Async Queue | Synchronous Queue | Visual Explanations | Part 1”
https://www.youtube.com/watch?v=6i0WnBRgUM0 -
“RabbitMQ Getting Started”
https://www.youtube.com/watch?v=sXwIpeYXses